
CQRS Pattern Explained: Discuss the Command Query Responsibility Segregation (CQRS) pattern.
In depth of CQRS Architectural Pattern

CQRS pattern separates the read and write operation for a datastore.
CQRS Youtube URL :
Understand the Requirements for CQRS
Let’s take an example of a retail chain organisation and they already have a monolithic solution in place, now they want to migrate to a microservices architecture on cloud.
The important fact from all analysis they have is most of the time they receive read calls to get product details and etc and around 30% they receives create calls.
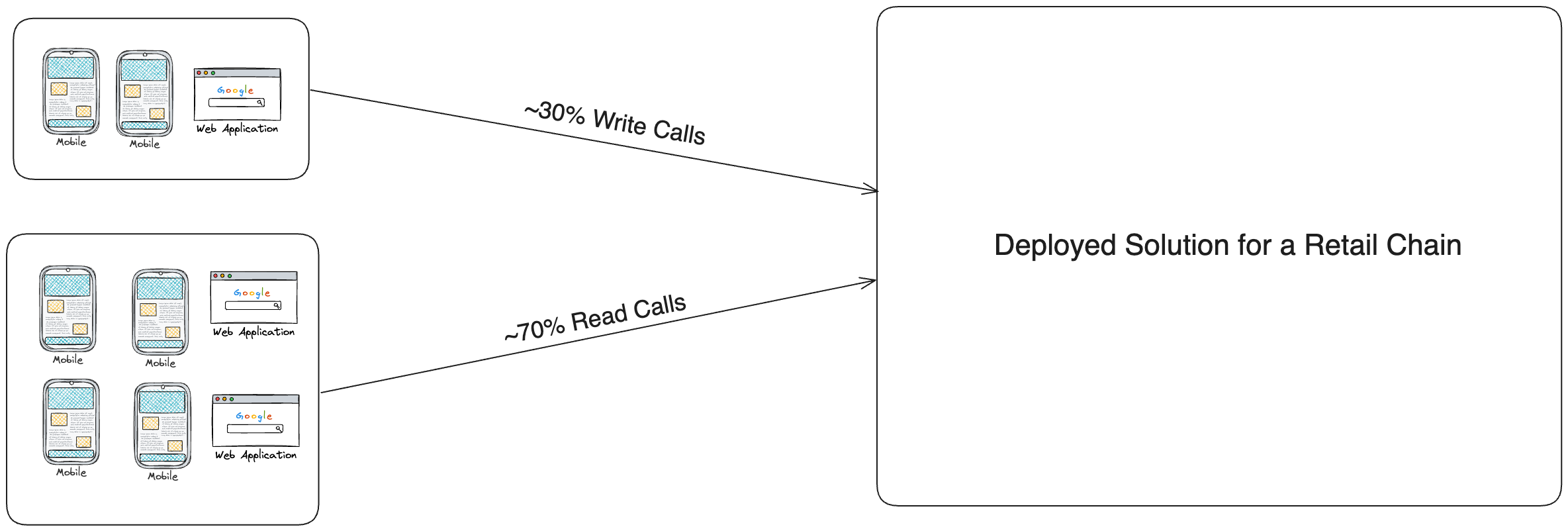
Another important requirement that pops up is they want faster read operations since 70% of the time system is consuming read calls.
Solution as CQRS
With above problem statement we understood that this retail chain is kind of a read heavy system, so it will be better if keep these two things separate and let’s call write and read operations as command.
So, on a high level solution for above deployed solution we will separate write and read domains.

Write domain handles all write operations - that modifies the state of data.
This will include create, update and deleting data.
Read domain will handle all read operations - which is to retrieve data without modifying it.
Benefits of CQRS
Scalability
Different scaling strategies can be applied to the command and query sides. For example, you might need more read replicas to handle a high volume of queries.
Performance
Optimising read and write operations separately can improve overall performance.
Separation of Concerns
By separating command and query responsibilities, the codebase can be more modular and easier to maintain.
Flexibility
Different data stores or models can be used for reading and writing, allowing for more flexibility in choosing the right tools for the job.
Implementing CQRS in a Microservices Architecture
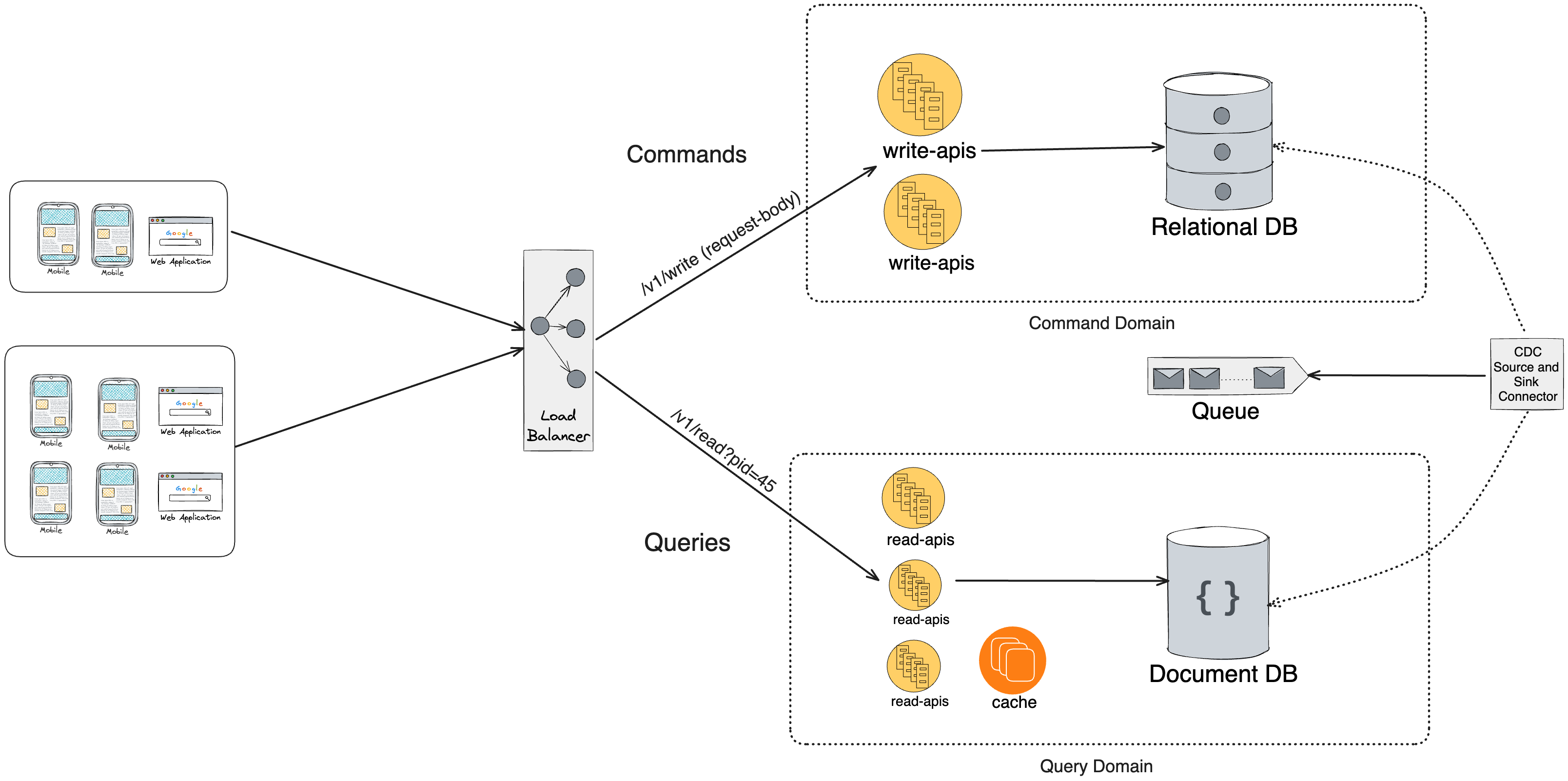
Let’s understand the architecture mentioned above.
Write-apis service will have all write apis ( all create, update and delete) operations which can be scale independently.
read-apis service will handle all read operations (GET) operations and these service can also be scaled independently.
Write service will write to a relational database lets say PostgreSQL.
CDC(Change data capture) source connector will identify there is a change happened, it will pick up that change and create an event for that and put it to an event queue.
CDC Sink connector will pick up that event and update it to document oriented database lets say Solr.
Since Solr has faster search capability (we could select any that is more preferable for read operation)
Next time, whenever a read request comes in for this particular change read-apis will lookup in solr and will fulfil that request.
the Entire point of having a CDC is to maintain a data synchronisation between two data stores.
Conclusion
Implementing CQRS in a microservices architecture involves separating the command and query responsibilities into different services, using event sourcing for state management, and synchronising data between the command and query models. This pattern can significantly enhance the scalability, performance, and maintainability of your system.
If you really like my content you can subscribe me below.
Youtube Channel - https://www.youtube.com/channel/UCpF3Y8AxzgYZnI8Zcf_G_fg
You can follow me on linkedin here - https://www.linkedin.com/in/suchait-gaurav-944479109/
Github Repo - https://github.com/suchait007